Der Unterschied zwischen statischem Training und dynamischem Lernen in Hörsystemen
Elementarer Bestandteil moderner Hörsysteme sind die Analyse und Klassifizierung der vorliegenden Hörumgebung, um die Signalverarbeitung des Hörsystems dementsprechend adaptiv anzupassen. Ziel der Klassifizierung ist es, den Hörverlust in jeder Hörsituation optimal auszugleichen, eine natürliche Klangwiedergabe bei bestmöglicher Sprachverständlichkeit zu gewährleisten sowie kognitive Ressourcen freizusetzen (Kuk, 2017).
Eine Vielzahl komplexer Hörsituationen kann so adaptiv durch die Signalverarbeitung berücksichtigt werden. Über die Zusammensetzung des Eingangssignals ist es möglich, die aktuelle Hörsituation einzuordnen. Zur Kategorisierung greifen Widex-Hörsysteme auf zwölf Attribute (z. B. die Modulation der Signaleinhüllenden, die Amplitudenmodulation usw.) zurück (Kuk, 2017). Das Signal wird in bis zu elf Hörwelt-Kategorien (z. B. Fahrzeug ohne Sprache, Gesellschaft mit Sprache, Musik usw.) adaptiv verarbeitet. Um eine solche Analyse zu bewerkstelligen, wird eine Art Training des Chipsets notwendig. Hierbei werden Hunderte bilateraler Aufzeichnungen, die realen Hörsituationen von Hörsystemträgern entsprechen, herangezogen. Durch das Training lernt das Hörsystem, akustische Attribute mit den jeweiligen Situationen des Alltags zu verknüpfen und die entsprechenden Parameter der Signalverarbeitung zu aktivieren (Kuk, 2017). Zusammen mit der individuellen Anpassung durch die Hörakustiker bildet die Klassifizierung ein essenzielles Element der Versorgung von Hörverlusten. Dennoch basieren die Entscheidungen der Klassifizierung auf den Annahmen, die der Hörsystem- Chip einmalig durch seine Programmierung erlernt hat. Dieses Trainingsverfahren lässt sich folglich als statisch beschreiben. Obwohl die akustische Einordnung der Automation in vielen Fällen zutrifft, kann sie nicht zu jeder Zeit für jeden Nutzer die gewünschten Erwartungen erfüllen (Balling et al., 2019).
Um der menschlichen Klangempfindung in den unterschiedlichsten Hörumgebungen besser Rechnung tragen zu können, bedarf es zusätzlich eines dynamischen Lernverfahrens. Denn unsere Klangempfindung ist häufig mit Intentionen verknüpft und daher wechselhaft (Townend et al., 2018a). So können Hörsystemträger, die grundsätzlich zufrieden mit ihrer Versorgung sind, in einzelnen Hörsituationen eine weitere Optimierung des Klangeindrucks wünschen. Diese individuellen Wahrnehmungswünsche können von einer automatischen Steuerung der Signalverarbeitung nicht berücksichtigt werden, da ihr die Intention der Hörsystemträger nicht bekannt ist. So kann es in ein und derselben Hörsituation zu unterschiedlichen Vorstellungen des Klangeindrucks kommen, obwohl die akustische Umgebung vom Hörsystem richtig identifiziert wurde.
Die Hörintention eines Hörsystemträgers kann aufgrund individueller Einflussfaktoren variieren, z. B. durch die persönliche Stimmungslage oder einen unterschiedlichen Kontext der jeweiligen Hörsituation. Ein Beispiel: Sitzt ein Hörsystem-Träger in einem Café, um ein Buch zu lesen, beabsichtigt er gegebenenfalls, eine andere akustische Wahrnehmung seines Umfelds als beim Treffen mit seinen Freunden in der identischen akustischen Hörumgebung (Müller, 2019).
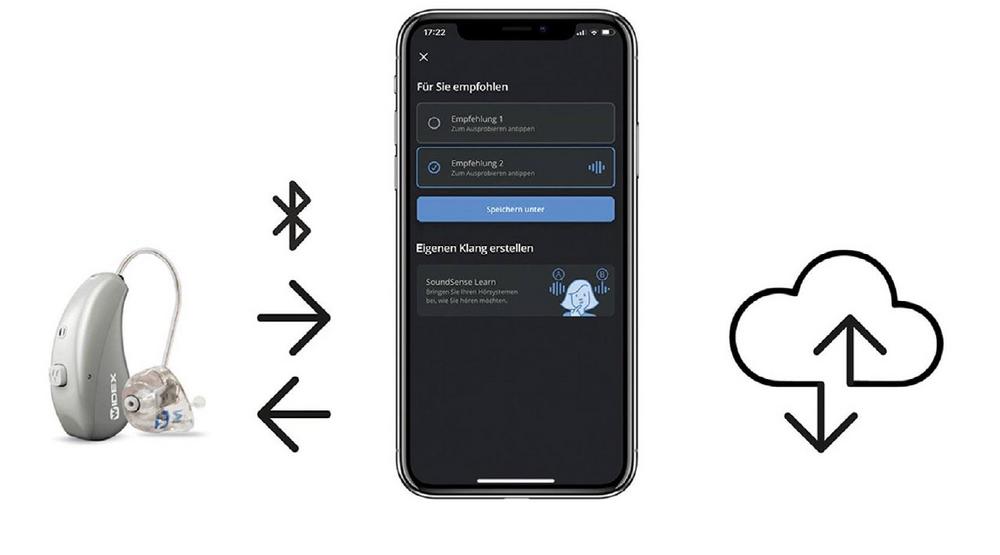
Durch das von Widex entwickelte KI-Lernsystem SoundSense Learn entsteht eine Schnittstelle zwischen Mensch und Maschine, die es ermöglicht, dem Hörsystem die eigenen Klangvorlieben unkompliziert und fortlaufend zu vermitteln. In Verbindung mit der externen Rechenleistung eines Smartphones (siehe Abbildung 1) verwendet das Hörsystem ein Machine-Learning-Verfahren. Dieses ist in der Lage, die Klangwiedergabe in Echtzeit an die individuellen Bedürfnisse seiner Anwender anzupassen (Townend et al., 2018a/b). Im Vergleich zu einer statisch trainierten Situationserkennung geht SoundSense Learn somit dynamisch auf Änderungswünsche in der jeweiligen Hörsituation ein. Diese Individualisierungen können als persönliches Programm gespeichert und – nur mit der Zustimmung der Nutzer – anonymisiert zur weiteren Analyse in eine sichere Widex-Cloud geladen werden.
Klangoptimierung durch Machine-Learning
Empfinden Hörsystemträger für die aktuelle Situation den Wunsch, ihren Klangeindruck zu optimieren, können sie den Machine-Learing-Algorithmus über die Hörsystem-App starten. Nachdem die Nutzer in der App die aktuelle Hörsituation und die vorliegende Hörintention ausgewählt haben, berechnet die KI über die Durchführung von A/B-Vergleichen kontinuierlich eine individuelle Lösung für die Klangintention (siehe Abb. 2). Hierzu werden in Echtzeit zwei unterschiedliche Klangeindrücke über das Hörsystem angeboten (Option A oder B). Anschließend entscheidet der Anwender, welche Auswahl er bevorzugt. Das Machine-Learning-Verfahren erlernt so schrittweise den angestrebten Klangeindruck und bindet die gelernten Informationen in die Berechnung der nächsten A/BVergleiche ein, bis das Ziel erreicht ist (Nielsen, 2014). Die unterschiedlichen Höreindrücke (A/B) erfolgen durch eine Veränderung der Verstärkung mittels 3-Band-Equalizer (Tiefen/Mitten/Höhen) (Balling et al., 2019). Das Verfahren ermöglicht seinen Anwendern, in unter 15 Vergleichen ihre individuelle Klangvorstellung abzudecken.
Besonders beeindruckend ist dieser Wert, da sich durch die 13 möglichen Einstellpositionen des 3-Band-Equalizers, 2.197 unterschiedliche Einstellmöglichkeiten ergeben. Um all diese Einstellungen miteinander zu vergleichen, würde ein Mensch 2,4 Millionen Direktvergleiche benötigen (Townend et al., 2018b). Natürlich wäre dies nicht praktikabel, da wir Menschen zu viel Zeit aufwenden müssten und nicht in der Lage sind, so viele Informationen zu verarbeiten und miteinander zu vergleichen.
Die zugrunde liegenden Anpassungen der Hörakustiker und die Einstellung der Klassifizierung der adaptiven Signalverarbeitung bleiben dabei unverändert. Das dynamische Machine-Learning-Verfahren bietet den Hörsystemträgern jedoch darüber hinaus eine zusätzliche Ebene der Individualisierung. Dieser Mehrwert wird durch eine gesteigerte Bewertung der Klangqualität und des Hörkomforts in einer Doppelblindstudie von Hörsystemträgern widergespiegelt (Jensen et al., 2019; Jensen & Townend, 2019). Zusätzlich erzielt das Machine- Learning-Feature SoundSense Learn eine überzeugend hohe Weiterempfehlungsrate von 80 Prozent (Balling et al., 2019). Die Ergebnisse deuten darauf hin, wie wichtig eine Teilhabe am Hören über die Hörsysteme für Menschen mit einer Hörminderung ist. Zudem stellen die Ergebnisse den willkommenen Nutzen für Hörgeräteträger heraus, in einzelnen Situationen unkompliziert eine komfortable Lösung auswählen zu können.
Die zugrunde liegenden Anpassungen der Hörakustiker und die Einstellung der Klassifizierung der adaptiven Signalverarbeitung bleiben dabei unverändert. Das dynamische Machine-Learning-Verfahren bietet den Hörsystemträgern jedoch darüber hinaus eine zusätzliche Ebene der Individualisierung. Dieser Mehrwert wird durch eine gesteigerte Bewertung der Klangqualität und des Hörkomforts in einer Doppelblindstudie von Hörsystemträgern widergespiegelt (Jensen et al., 2019; Jensen & Townend, 2019). Zusätzlich erzielt das Machine- Learning-Feature SoundSense Learn eine überzeugend hohe Weiterempfehlungsrate von 80 Prozent (Balling et al., 2019). Die Ergebnisse deuten darauf hin, wie wichtig eine Teilhabe am Hören über die Hörsysteme für Menschen mit einer Hörminderung ist. Zudem stellen die Ergebnisse den willkommenen Nutzen für Hörgeräteträger heraus, in einzelnen Situationen unkompliziert eine komfortable Lösung auswählen zu können.
Nach Zustimmung der Hörgeräte-Träger können die erstellten Programme auf zwei Wegen weiter untersucht werden:
(1) Sie stehen dem betreuenden Hörakustiker über das Real-Life-Insights-Feature der Anpasssoftware zur Verfügung. Dies dient zur Etablierung eines ganzheitlichen Optimierungs-Systems. Es setzt dabei voraus, dass die Hörsysteme vor Ort über die Anpassoftware Compass GPS verbunden werden. Die Hörakustiker werden in einer Art Data-Logging-Verfahren über die Verwendung und Einstellung der individuellen Lieblingsprogramme informiert. Diese Erkenntnisse erlauben mehr Einblicke in die individuellen Bedürfnisse der Hörsystemträger und dienen als Beratungsgrundlage bzw. Zusatzinformationen für eine Feinanpassung.
(2) Die von den Anwendern über das Machine-Learning-Verfahren in der Widex-Cloud zur Verfügung gestellten Daten dokumentieren zusätzlich Verhaltensmuster auf Gruppenebene und helfen Widex, zukünftige Lösungen für Hörsystemträger zu entwickeln.
Machine-Learning-Daten: Eine Übersicht
Die in der Cloud gespeicherten anonymen Datensätze enthalten Informationen über die von den Anwendern ausgewählten Hörsituationen und -intentionen. Hinzu kommt die resultierende Einstellung des Equalizers, die dem Lieblingsprogramm zugrunde liegt. Zugleich verschaffen die Daten einen Überblick, in welchen Hörumgebungen Anwender eine KI-Unterstützung genutzt haben. Ein Beispiel hierfür zeigt Abbildung 3. Zu sehen ist das Verhältnis der gespeicherten SoundSense-Learn-Programme für den Zeitraum des ersten Halbjahres 2020. Erstellte KIProgramme wurden für eine bessere Übersicht in sechs Kategorien aufgeteilt.
Datenanalyse für weitere Entwicklungen
Neben der Auswertung über die Hörsituationen sind die Ergebnisse der individuellen KI-Programme von höchstem Interesse. Seit 2018 wurden Hunderttausende persönliche KI-Programme erstellt und abgespeichert, wobei deren Anzahl permanent weiterwächst. Abbildung 4 zeigt eine randomisierte Auswahl der gespeicherten und regelmäßig verwendeten Programme für den Zeitraum zwischen März und Oktober 2020. Um eine grafische Darstellung dieser Daten zu ermöglichen, wurde die Auswahl für Abbildung 4 auf 20.000 Lieblingsprogramme begrenzt.
Jeder Punkt stellt ein Programm dar; teilen sich mehrere Programme dieselben Einstellungen des 3-Band- Equalizers (Tiefen/Mitten/Höhen), werden sie mit einer Schattierung dargestellt. Begrenzt ist die KI-Lernweite über die Regeltiefe des Equalizers. Das Verhältnis aller erfassten SSL-Programme erstreckt sich gleichmäßig über den dreidimensionalen Raum. Grundsätzlich lassen sich hieraus zwei Schlüsse ziehen:
(1) Die individuell unterschiedlichen Bedürfnisse der Hörsystemträger könnten nicht über eine einzelne Veränderung der zugrunde liegenden Anpassformel abgedeckt werden. Dies wäre notwendig, wenn sich ein Großteil der Programme in einem Bereich des Würfels sammelt.
(2) Auf den ersten Blick ist es nicht möglich, tiefere Zusammenhänge zwischen den persönlichen Programmen herzustellen. Es bedarf des Einsatzes weiterer Untersuchungen, um mehr Einblicke in die KI-erzeugten Daten zu erhalten. Eine Möglichkeit, die Daten detaillierter zu interpretieren, ist die Analyse aller A/B-Vergleiche, die zu einer präferierten Einstellung führten. Somit betrachtet dieses Verfahren nicht nur das Endergebnis, sondern auch den Weg, den ein Anwender bis zum Ziel zurückgelegt hat. Der Machine-Learning-Vorgang kann demnach auch als Präferenz-Sensor verstanden werden, der die Präferenz-Optimierung für eine personalisierte Einstellung abbildet (Nielsen et al., 2019).
Zusätzliche Analyse-Funktion durch eine duale KI
Durch die Komplexität der Daten reicht es nicht aus, diese für weitere Erkenntnisse nur abzubilden. Die Machine- Learning-Ergebnisse müssen verknüpft mit der persönlichen Hörsituation und -intention durch eine zweite KI auf einen Zusammenhang untersucht werden. Für weltweit erstellte persönliche Programme erforscht eine Big- Data-Analyse die Verläufe der A/B-Vergleiche, die zu den jeweiligen finalen Einstellungen des Equalizers führten.
Anhand der Verknüpfung und Analyse dieser Informationen ist es möglich, aus allen bekannten Programmen Vorschläge zu entwickeln, die den Anwendern in einer vergleichbaren Hörsituation direkt zur Verfügung stehen.
Für die Berechnung der Vorschläge einer Hörsituation greift die Big-Data-Analyse aus Berechnungsgründen auf maximal 32.000 A/B-Vergleiche zurück. Um den KI-Nutzern die positiven Erfahrungen aller Anwender zur Verfügung zu stellen, bedarf es folgender drei Analyseschritte:
Schritt 1: Konstruktion eines Wahrscheinlichkeitsmodells (Gauß-Prozess-Modell) (Nielsen et al., 2015): Errechnet in der jeweiligen Hörsituation die Wahrscheinlichkeiten aller möglichen Kombinationen über die drei Equalizer- Parameter, die durch SoundSense Learn gesteuert werden.
Schritt 2: Das Gauß-Prozess-Modell errechnet 10.000 Muster, die als vorausgesagte oder ideale Programme verstanden werden können. Diese „virtuellen Programme“ spiegeln die Präferenz über die A/B-Vergleiche aller Anwender in einer bestimmten Hörsituation wider.
Schritt 3: Über den Meanshift Clustering Algorithm (Comaniciu & Meer, 2002) wird das Muster der 10.000 vorausgesagten Programme einer Situation präzise in Clustern zusammengefasst. Die beiden stärksten Cluster erhalten Anwender der KI über die App als vorberechnete Klangvorschläge für die Hörsituation, in der eine Unterstützung angefragt wurde.
Wichtig zu wissen ist, dass jedes der von der KI vorausgesagten 10.000 Programme (Schritt 2) ein guter Vorschlag für einen spezifischen Anwender in der jeweiligen Situation wäre. Die Zusammenfassung in sogenannten Clustern (Gruppen) ermöglicht jedoch ein klareres Verständnis über das Muster der errechneten Programme (Balling et al., 2021). Aus den Berechnungen der Big-Data-Analyse zeigt sich, dass es für jede Situation eine Reihe systematischer Gruppen gibt, die einen großen Anteil der situativen Programme vertreten. Dabei ist deren Repräsentationsgrad hoch. Die zwei stärksten Gruppen decken für die unterschiedlichsten Hörsituationen durchschnittlich drei Viertel aller individuellen Programme ab (Repräsentationsgrad: M = 79 %; Min. = 49 %, Max. = 100 %). Wie genau zwei Gruppen die Bedürfnisse aller Anwender abdecken werden, wird von der Komplexität der Hörumgebung beeinflusst. Die Ergebnisse der Analyse zeigen, dass für die Situation „Transport“ bereits die stärkste Gruppe 100 Prozent des Bedarfs abdeckt. Komplexere Situationen wie in Unterhaltungen in verschiedenen Räumlichkeiten und mit unterschiedlicher Personenanzahl werden durch die beiden stärksten Gruppen zu 49 Prozent abgedeckt (Balling et al., 2021).
Eine Veranschaulichung der Gruppenbildung findet sich für die Situation „Abendessen“ in Abbildung 5. Die in Blau abgebildete Gruppe deckt mit 64 Prozent den Großteil aller Fälle ab. Mitten und Höhen des Equalizers wurden für diese Einstellung reduziert, während der Tiefton-Bereich unverändert blieb. Dies könnte auf Anwender zurückzuführen sein, die das Besteckklappern reduzieren wollten. Die zweithäufigste Gruppe (orange) spiegelt zwölf Prozent aller Programme wider. Diese Einstellung erhöht Equalizer-Bänder für Tiefen und Mitten, wobei die Höhen annähernd unangetastet bleiben. Ein möglicher Hintergrund könnte eine weitere Steigerung der Sprachverständlichkeit sein. Wichtig zu verstehen ist, dass es sich bei dieser Analyse der einzelnen Cluster um Vermutungen handelt. Sie beschreiben mögliche Anforderungen vieler Anwender, beziehen sich jedoch nicht auf das individuelle Bedürfnis einzelner (Balling et al., 2021).
Umsetzung der dualen KI: Widex MY SOUND
Nutzer von Widex Moment Bluetooth-Hörsystemen können über die Moment App 1.2 auf das Widex Feature My Sound zurückgreifen. My Sound vereint beide hier vorgestellten KI-Anwendungen: (1) SoundSense Learn zur individuellen Klangoptimierung via Machine Learning sowie (2) den Vorschlag der beiden besten Cluster der Big- Data-Analyse. Die beiden errechneten Vorschläge aus den weltweiten Erfahrungen können in der aktuellen Situation angehört und miteinander verglichen werden. Sollte keiner der zwei Vorschläge den gewünschten individuellen Wunsch abdecken, ist es den Anwendern weiterhin möglich, über SoundSense Learn eine persönliche Klangfindung durchzuführen. Da die Ergebnisse dieses Vorgangs wiederum in die Analyse der Clouddaten fließen, lernt My Sound stetig von den dynamischen Bedürfnissen seiner Anwender. Dies ermöglicht eine fortlaufende Weiterentwicklung der KI-Vorschläge – trainiert über die tägliche Anwendung echter Nutzer in realen Hörsituationen.
My Sound erlaubt einen noch schnelleren Zugang zum bevorzugten Klangeindruck für die jeweilige Hörsituation, verbunden mit der persönlichen Hörintention. Hörsystemträger profitieren von der Echtzeit-KI-Technologie, indem ihnen ein starkes Werkzeug zur Verfügung steht, mit dem sie ihren Klang in der aktuellen Umgebung weiter verfeinern können. So lassen sich z. B. Klangqualität und Hörkomfort bei Bedarf steigern. Dies ist für den alltäglichen Umgang mit Hörsystemen von hoher Relevanz, da My Sound den Hörsystemträgern eine höhere Teilhabe an der Wahrnehmung ihrer Hörwelt erlaubt. Zugleich bietet es Hörsystemträgern die Sicherheit, dass eine sofortige Lösung zur Verfügung steht. Dabei verwendet My Sound immer die optimale Einstellung der Hörakustiker und die adaptive Klassifizierung der Signalverarbeitung als essenzielles Fundament für die zusätzliche persönliche Optimierung.
Die KI-Optimierung bietet Hörakustikern eine zusätzliche Option für eine effiziente Versorgungsstrategie. So ermöglicht My Sound, den weiteren Einblick in unterschiedliche Hörsituationen und Bedürfnisse der Hörsystemträger zu erhalten. Dies kann für die Entwicklung neuer Strategien in der Feinanpassung, z. B. für die Verfeinerung eines Musikprogramms, genutzt werden. Darüber hinaus reduziert die KI-Lösung My Sound die Komplexität der Nachanpassung, denn spezielle Höransprüche können durch die Hörsystemträger direkt vor Ort bearbeitet werden. Dies führt zu einer zielgerichteten Feinanpassung im Fachgeschäft und führt zu weniger Nachstellterminen für gegebenenfalls selten auftretende akustische Situationen.
Zusammenfassung
Im Vergleich zu einem einmalig hinterlegten Training des Hörsystem-Chips, das von adaptiven Signalverarbeitungen zur Hörsituationserkennung genutzt wird, entspricht die künstliche Intelligenz von My Sound einem fortlaufenden Lernverfahren. Neben der Kombination aus Feinanpassung der Hörakustiker und einer adaptiven Situationserkennung lässt sich über die Verwendung zweier dynamisch lernender KIs zusätzlich die individuelle Hörintention der Hörsystemträger für die Schallwiedergabe berücksichtigen. Das Echtzeit-Lernverfahren kann vor Ort durch den Hörsystemträger ausgelöst werden. Dies erlaubt es der KI, von den jeweiligen Hörintentionen der Anwender zu lernen, um den Klang weiter anzupassen.
Widex My Sound verfügt über zwei KI-Ansätze, die über die Moment-App 1.2 zur Verfügung stehen. Durch eine Big- Data-Analyse bereits abgespeicherter persönlicher KI-Programme erhalten Anwender zwei Klangvorschläge für ihre jeweilige Hörsituation. Die Vorschläge beruhen auf den individuellen Programmen weltweiter Nutzer, die diese in vergleichbaren Situationen erstellt und verwendet haben. Des Weiteren besteht die Möglichkeit, über die Machine- Learning-Anwendung SoundSense Learn den individuellen Hörsystemklang für spezielle Situationen in unter 15 A/B-Vergleichen zu entwickeln. Die KI erlernt hierbei anhand der vorliegenden Hörintention den gewünschten Klangeindruck der Hörsystemträger. Sobald diese Einstellungen als persönliches Programm gespeichert werden, fließen diese Informationen anonymisiert in weitere Analysen ein. So entwickelt sich My Sound über seine duale KI stetig nach den Bedürfnissen der Hörsystemträger weiter und ermöglicht einen bedeutenden Fortschritt für die Klangoptimierung.
Dieser Artikel erschien ursprünglich in der Ausgabe 05/2021 der "Hörakustik".
Autor:
Simon Müller ist seit 2017 audiologisch-wissenschaftlicher Leiter bei der Widex Hörgeräte GmbH in Stuttgart. Nach einem Bachelor in Augenoptik und Hörakustik an der Hochschule Aalen im Jahr 2011 erlangte er 2012 den Master of Science in Audiology an der University of Manchester. Praktische Erfahrung sammelte er als Betriebsleiter eines Hörakustikfachgeschäfts und als audiologischer Leiter an der Rheinisch-Westfälischen Technischen Hochschule (RWTH) Aachen.
Quellen:
Balling L W, Townend O, Switalski W. (2019). Real-life hearing aid benefit with Widex EVOKE. Hearing Review.
2019; 26(3) [Mar]: 30–36.
Balling L W, Townend O, Molgaard L, Switalski W. (2020). Expanding your hearing care beyond the walls of your clinic. Hearing Review. 2020; 27(10): 22–25.
Balling L W, Townend O, Molgaard L L, Jespersen C B, Switalski W. (2021). AI-driven insights from AI-driven data.
Hearing Review. 2021; 28(1): 22–25.
Comaniciu D, Meer P. (2002). Mean shift: A robust approach toward feature space analysis. IEEE Trans Pattern Anal Mach Intell. 2002; 24(5): 603–619.
Jensen N S, Hau O, Nielsen J B B, Nielsen T B, Legarth S V. (2019). Perceptual effects of adjusting hearing-aid gain by means of a machine-learning approach based on individual user preference. Trends Hear. 2019; 23.
Jensen N S, Townend O. (2019). Machine learning in Widex EVOKE: Perceptual benefits of SoundSense Learn.
Widex Press. https://bit.ly/3cBcQ2D. Published May 2019.
Kuk F. (2017). Going BEYOND: A Testament of Progressive Innovation. Hearing Review Feb 20, 2017.
Müller S. (2019). Warum Hörsysteme durch künstliche Intelligenz von uns lernen sollten, Hörakustik 06/2019; 8–12.
Nielsen J B. (2014). System for Personalization of Hearing Instruments – A Machine Learning Approach. Danish Technical University (DTU). https://backend.orbit.dtu.dk/…
(Stand: 22.03.2021).
Nielsen J B B, Nielsen J, Larsen J. (2015). Perception-based personalization of hearing aids using Gaussian processes and active learning. IEEE/ACM Trans Audio Speech Lang Process. 2015; 23(1): 162–173.
Nielsen J B B, Mølgaard L L, Jensen N S, Balling L W. (2019). Machine-learning based hearing-aid personalization:
Preference optimizer, preference sensor or both? 7th International Symposium on Auditory and Audiological Research. 2019: 40.
Townend O, Nielsen J B, Balslev D. (2018a). SoundSense Learn – Listening Intention and Machine Learning. Hearing Review 25 (6); 28–31.
Townend O, Nielsen J B, Ramsgaard J. (2018b). Real-life applications of machine learning in hearing aids. Hearing Review. 2018; 25(4): 34–37.
Widex Hörgeräte GmbH
Epplestraße 225
70567 Stuttgart
Telefon: +49 (711) 7895-0
Telefax: +49 (711) 7895-200
http://www.widex-hoergeraete.de
Content Managerin
Telefon: 0711/7895-152
E-Mail: peggy.reiss@widexsound.com
![]()